定期的に spreadsheet を取得しにいくものを作りたい。
よくある要件なのだがハマったところがあったのでひととおりメモしておく。
サンプル一式
Github にサンプル上げましたので、よかったらどうぞ
認証
Service account の作成
Google API を叩くときによく使われるのは OAuth Client だが、今回はユーザーによる認証ではなくシステム利用を目的としているので Service account を作成する。
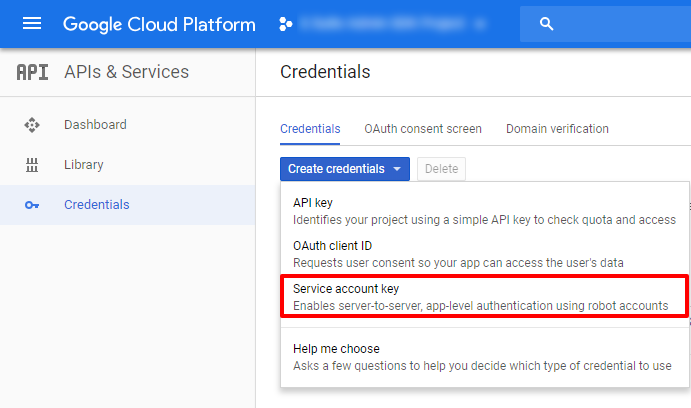

今回は Lambda から叩くので適当な名前をつける。
このメールアドレスが Google ユーザー名のような扱いになるので、本稼働させる場合はなんの Service account か分かる名前にしましょう。
オプション: Service account への権限委任
Perform G Suite Domain-Wide Delegation of Authority | Directory API | Google Developers今回は必要ないので設定していませんが、Service account がユーザーの認証なしにユーザーデータにアクセスできるようにすることができます。
Admin API を使いたいときもこれを利用します。
2019/07/08追記:
Service accountの設定にあった委任チェックボックスはなくなりました。
後述しているSCOPEの許可設定のみで委任できます。
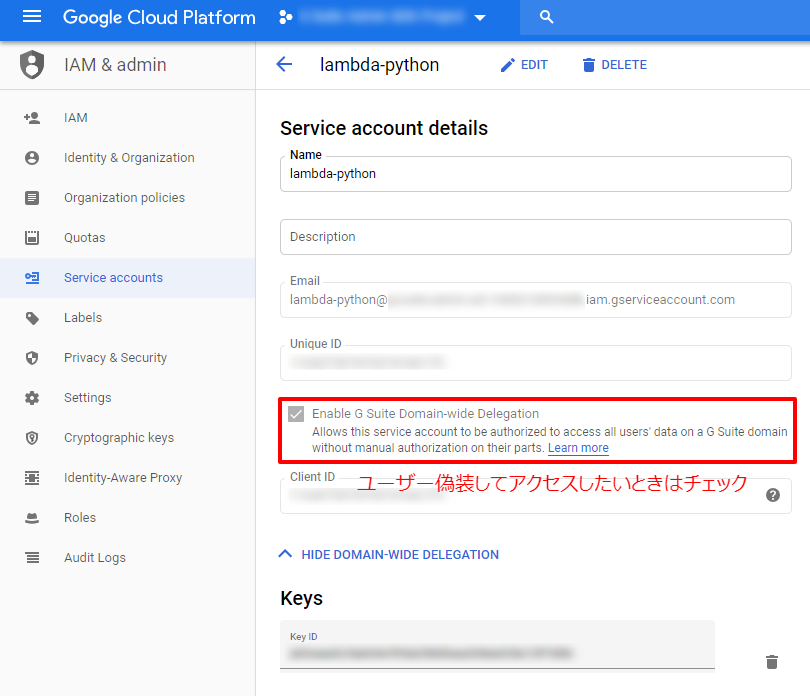
G Suite 管理画面から Service account にどの SCOPE を許可するか設定することで、委任の範囲を指定することができます。
Lambda から Google API を呼ぶ
Service account の Credential は Secret Manager に入れて Lambda から呼ぶようにしています。
初めて使ってみたんですが便利ですね Secret Manager。
Secret Manager から GetSecretValue すると復号化も勝手にやってくれますが、暗号化した KMS キーに対して kms:Decrypt の権限が必要になります。Role への権限付け忘れに注意。
実際に呼ぶのは公式の google-api-python-client 使っています。
Lambda Layer 好きなので Layer として登録して Lambda から使いました。
cache_discovery=False を付けないとエラーになったので付けてます。
このあたりはよくわかってない。
credentials = service_account.Credentials.from_service_account_info(
service_account_info, scopes=SCOPES)
self.service = build('sheets', 'v4', credentials=credentials,
cache_discovery=False)
定期実行 CloudWatch Event は SAM でテンプレートを書いているので数行追加するだけで OK。
素の CFn テンプレートのほうが慣れてるんですが SAM もいいですね。
Events:
HourlyEvent:
Type: Schedule
Properties:
Schedule: rate(10 minutes)
Sheet Response
辞書型で返してほしかったので、こんな感じで返るようにしています。
{'id': '1001', 'name': 'hogehoge', 'address': 'shinjuku', 'mail': '[email protected]'}
{'id': '1002', 'name': 'fugafuga', 'address': 'meguro', 'mail': '[email protected]'}
Drive Response
Spreadsheet はファイルとして出力するときは mineType を指定する必要があるので text/csv として出力。
Download してから csv を呼んでいるのでこんな感じ。
OrderedDict([('id', '1001'), ('name', 'hogehoge'), ('address', 'shinjuku'), ('mail', '[email protected]')])
OrderedDict([('id', '1002'), ('name', 'fugafuga'), ('address', 'meguro'), ('mail', '[email protected]')])
TeamDrive 対応
fileId を決め打ちで export_media するときは関係ないのだが、 list や get などをするときは TeamDrive 特有のパラメータが必要になってくる。
list で取得するときなにかと Team 系パラメータを付ける必要があった。
teamDriveId は任意だったはず。
なにが必須でなにが任意なのかわからなくてハマった。
results = self.service.files().list(
pageSize=50,
fields="nextPageToken, files(id, name, webContentLink)",
supportsTeamDrives=True,
includeTeamDriveItems=True,
corpora="teamDrive",
teamDriveId=teamdrive_id).execute()
get のときは supportsTeamDrives が必要。
export_media はいらないのに……パラメータの必須度がちぐはぐしている。
metadata = self.service.files().get(
fileId=file_id,
supportsTeamDrives=True).execute()